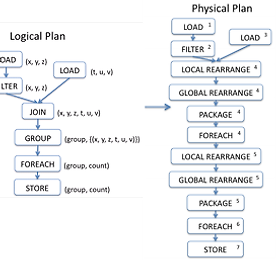
하둡 썸네일형 리스트형 flume error 해결 org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritable flume error 해결 org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritable 해결에 참고한 내용http://mail-archives.apache.org/mod_mbox/flume-user/201301.mbox/%3CDA2B926AB70E406B991A25705557610B@cloudera.com%3E 입력되는 값문자열이 탭으로 구분된 데이터 sfae a;ldfja;sldj alwkejhfalskdhf a;slekjafabcd def de ab d eef ddefsef sfae a;ldfja;sldj alwkejhfalskdhf a;slekjafabcd def de ab d eef ddefsef sfae a;ldfja;sldj alw.. 더보기 윈도우 하둡 스터디 하면서 본 MS 한글 문서 Getting Started Azure HDInsight 한글 문서들 Window hadoop 윈도우 하둡 스터디 하면서 본 MS 한글 문서 Getting Started Azure HDInsight 한글 문서들 Window hadoop 윈도우 하둡 종류 정리 http://paranwater.tistory.com/450 Blob에대해 잘 설명한 글 - 글 상단에 간단하게 설명 되어있습니다 http://www.taeyo.net/Columns/View.aspx?SEQ=417&PSEQ=33#3 아래 번호 순서대로 읽으면서 전체적인 개념을 파악할 수 있었습니다모두 한글 문서 입니다 HDInsight 전체 자습서 및 가이드 목록http://azure.microsoft.com/ko-kr/documentation/services/hdinsight/ Azure HDInsight를 사용하여 시작Getting Sta.. 더보기 윈도우 하둡 종류 정리 [window hadoop] 윈도우 하둡 종류 정리 [window hadoop] 윈도우용으로 사용할 수 있는 하둡들입니다윈도우용 하둡은 Hortonworks 제품이 사용되고 있습니다 기타 : hadoop streaming 소개 http://paranwater.tistory.com/386 HortonworksQuick Guide : http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1-Win-latest/bk_installing_hdp_for_windows/content/win-chap2-singlenode.html호튼웍스에서 제공하는 하둡입니다원클릭으로 설치가되며 호튼웍스 사이트에가면 해당 주제로 커뮤니티도 구성되어 있어 도움 받을 수도 있습니다윈도우 직접 설치해서 사용합니다 Window .. 더보기 윈도우 하둡 window hadoop HDInsight Azure 압축 호환에 관련된 글 (Gzip, Bzip2, LZO, LZ4, snappy) 윈도우 하둡 window hadoop HDinsight Azure 압축 호환에 관련된 글 (Gzip, Bzip2, LZO, LZ4, snappy) 문서 다운로드 https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0CCQQFjAA&url=http%3A%2F%2Fdownload.microsoft.com%2Fdownload%2F1%2FC%2F6%2F1C66D134-1FD5-4493-90BD-98F94A881626%2FCompression%2520in%2520Hadoop%2520(Microsoft%2520IT%2520white%2520paper).docx&ei=efxBVOydHqfMmAWHu4KoCg&usg=AFQjCNEMlCpXoTbqzo.. 더보기 Spark Cluster Manager Types (스파크 클러스터 매니저 타입 3종류 번역) Spark Cluster Manager Types3종류를 발번역 하였습니다 전체적인 흐름을 파악하는데 참고해주세요 스파크 워드 카운트 소스코드 주석달면서 분석중 http://paranwater.tistory.com/416 원문 페이지 주소 : http://spark.apache.org/docs/latest/cluster-overview.html 클러스터 관리자 유형 시스템은 현재 3종류의 클러스터 관리자를 지원합니다. Standalone – a simple cluster manager included with Spark that makes it easy to set up a 독립형 - 간단한 클러스터 매니저가 Spark에 포함되어있어 관리자는 클러스터를 쉽게 구성할 수 있습니다 Apache Mesos –.. 더보기 Hortonworks 샌드박스에 있는 Ambari 관련 내용 번역 입니다 (sandbox) Hortonworks sandbox 가상머신 내 링크http://가상머신 아이피 주소/ambari.html 아파치 링크http://incubator.apache.org/ambari/ Hortonworks 샌드박스에 있는 Ambari 관련 내용 번역 입니다 Apache Ambari - Making Hadoop easier to operate (아파치 Ambari - 하둡을 쉽게 작동 하도록 만들기)아파츠 Ambari는 아파치 하둡 클러스터를 모니터링하고 효율적으로 관리하기 위해 100% 오픈소스 도구로 직관적인 세트를 제공합니다. Ambari가 작어을 단순화 하고 하둡의 복잡성을 숨깁니다. 하둡을 하나로 모은 데이터 플랫폼 같은 화면으로 나타냅니다 참여 노드가 수백 또는 수천인 경우 하둡 클러스터 구축 및.. 더보기 윈도우 하둡 HDInsight 0.4.0 클러스터 구성 - window hadoop HDInsight cluster setting 윈도우 하둡 HDInsight 0.4.0 클러스터 구성 - window hadoop HDInsight cluster setting HDInsight 포럼에 있는 글을 참고 하여 클러스터를 구성했습니다 http://social.msdn.microsoft.com/Forums/en-US/hdinsight/thread/885efc22-fb67-4df8-8648-4ff38098dac6 HDInsight Preview server download http://www.microsoft.com/web/gallery/install.aspx?appid=HDINSIGHT-PREVIEW 구성 환경 - VirtualBox, Window Server 2012, 메모리 3G, 호스트 전용 네트워크 - master 1개, slave.. 더보기 Pig 동작 과정- 실행 계획 Pig 동작 과정- 실행 계획 Pig Latin으로 적은 명령은 논리적,물리적 실행 계획으로 변환되고 이것이 다시 Map Reduce 실행 계획으로 변환 후 실행됩니다 더보기 이전 1 2 다음