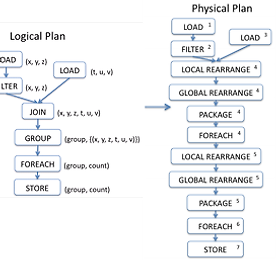
MapReduce 썸네일형 리스트형 context.getConfiguration(); java.lang.NullPointerException 문제 해결 context.getConfiguration(); java.lang.NullPointerException 문제 해결 hadoop MRjob을 작성하는중 나타난 트러블 슈팅 내용입니다환경은 CDH5.X버전이고 ubuntu14.04입니다 15/08/07 10:53:04 INFO input.FileInputFormat: Total input paths to process : 1 15/08/07 10:53:04 INFO mapreduce.JobSubmitter: number of splits:1 15/08/07 10:53:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1197195623_0001 15/08/07 10:53:04 INFO .. 더보기 HDInsight hadoop streaming C# map reduce test C#으로 맵 리듀스 코딩해서 HDInsight hadoop streaming 사용하는 방법 입니다HDInsight hadoop streaming C# map reduce test 관련된 다른 글hadoop streaming 소개Hadoop Streaming 구조HDInsight hadoop streaming C# map reduce test HDInsight hadoop-streaming-1.1.0-SNAPSHOT.jar을 이용 hadoop dfs -rmr a/hadoop dfs -mkdir a/hadoop dfs -put map.exe a/hadoop dfs -put reduce.exe a/hadoop dfs -put pic.txt a/필요한 파일을 하둡으로 put hadoop jar hadoop-st.. 더보기 Pig 동작 과정- 실행 계획 Pig 동작 과정- 실행 계획 Pig Latin으로 적은 명령은 논리적,물리적 실행 계획으로 변환되고 이것이 다시 Map Reduce 실행 계획으로 변환 후 실행됩니다 더보기 이전 1 다음