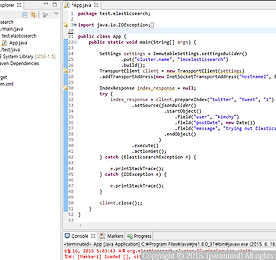
빅데이터 썸네일형 리스트형 context.getConfiguration(); java.lang.NullPointerException 문제 해결 context.getConfiguration(); java.lang.NullPointerException 문제 해결 hadoop MRjob을 작성하는중 나타난 트러블 슈팅 내용입니다환경은 CDH5.X버전이고 ubuntu14.04입니다 15/08/07 10:53:04 INFO input.FileInputFormat: Total input paths to process : 1 15/08/07 10:53:04 INFO mapreduce.JobSubmitter: number of splits:1 15/08/07 10:53:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1197195623_0001 15/08/07 10:53:04 INFO .. 더보기 flume error 해결 org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritable flume error 해결 org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritable 해결에 참고한 내용http://mail-archives.apache.org/mod_mbox/flume-user/201301.mbox/%3CDA2B926AB70E406B991A25705557610B@cloudera.com%3E 입력되는 값문자열이 탭으로 구분된 데이터 sfae a;ldfja;sldj alwkejhfalskdhf a;slekjafabcd def de ab d eef ddefsef sfae a;ldfja;sldj alwkejhfalskdhf a;slekjafabcd def de ab d eef ddefsef sfae a;ldfja;sldj alw.. 더보기 elasticsearch index client java api example mavne 프로젝트 기본 구조 elasticsearch index client java api example mavne 프로젝트 기본 구조 elasticsearch java api를 이용한 기본 코딩 입니다elasticsearch api문서보는게 익숙치 않다보니 삽질좀 하다가 성공했습니다 public class App {public static void main(String[] args) {Settings settings = ImmutableSettings.settingsBuilder().put("cluster.name", "imcelasticsearch").build();TransportClient client = new TransportClient(settings).addTransportAddress(new InetSocketTr.. 더보기 윈도우 하둡 스터디 하면서 본 MS 한글 문서 Getting Started Azure HDInsight 한글 문서들 Window hadoop 윈도우 하둡 스터디 하면서 본 MS 한글 문서 Getting Started Azure HDInsight 한글 문서들 Window hadoop 윈도우 하둡 종류 정리 http://paranwater.tistory.com/450 Blob에대해 잘 설명한 글 - 글 상단에 간단하게 설명 되어있습니다 http://www.taeyo.net/Columns/View.aspx?SEQ=417&PSEQ=33#3 아래 번호 순서대로 읽으면서 전체적인 개념을 파악할 수 있었습니다모두 한글 문서 입니다 HDInsight 전체 자습서 및 가이드 목록http://azure.microsoft.com/ko-kr/documentation/services/hdinsight/ Azure HDInsight를 사용하여 시작Getting Sta.. 더보기 윈도우 하둡 HDInsight 0.4.0 클러스터 구성 - window hadoop HDInsight cluster setting 윈도우 하둡 HDInsight 0.4.0 클러스터 구성 - window hadoop HDInsight cluster setting HDInsight 포럼에 있는 글을 참고 하여 클러스터를 구성했습니다 http://social.msdn.microsoft.com/Forums/en-US/hdinsight/thread/885efc22-fb67-4df8-8648-4ff38098dac6 HDInsight Preview server download http://www.microsoft.com/web/gallery/install.aspx?appid=HDINSIGHT-PREVIEW 구성 환경 - VirtualBox, Window Server 2012, 메모리 3G, 호스트 전용 네트워크 - master 1개, slave.. 더보기 이전 1 다음